

Name: weltschmerz
Location:
Posts: 2192
Location:
Posts: 2192
Executive summary for the hasty: these low picmip streams look good in 720p because that's the only resolution streamers are encoding themselves and having full control over. All other resolutions are encoded and resource capped by twitch, specifically in terms of bandwidth. That's why the other resolutions look as disastrous as they do.
As to the details, the following also includes a very rough look at video compression (or video "encoding") which is slightly technical. But it helps understanding what compression artifacts are and how they look like. Be warned though, once you know how to recognize artifacts you can't "unsee" them anymore. So those of you who tend to think that ignorance is bliss might want to stop reading right here.
(1) Streaming basics
For streaming, people use a broadcasting software, like XSplit, which serves multiple functions. It's a capturing software on the one hand, capable of grabbing and composing images and audio from various sources, like screen regions and web cams. Then it's a video and audio compressor that's substantially reducing the amount of bits that are needed to represent the media. And finally it's a networking application that's sending - streaming - the compressed output to some server, for redistribution to clients (YOU!).
The compression techniques involved are stuff we're encountering everyday when dealing with digital media. JPEG is a image compression method. MP3 the same for audio. DVDs are encoded in MPEG2, a video compression standard. And Blu-Rays and HD TV broadcasting streams are encoded in MPEG4, the very same compression technique that's used by gaming streamers these days.
All these compression standards have one goal: reduce the bandwidth it needs to represent the media. To reduce the amount of data that needs to be sent over the network when streaming. Or to reduce the file size when storing the media on disk.
Regarding video, the basic approach is pretty much always the same. First perform some lossy compression that simply throws away data the human eye isn't that sensitive to anyway. Then try to merely store differences - "deltas" - between frames resp. even parts of a single frame.
The "delta" approach - and quakers will love this even though the meaning is a completely different one from what we're used to - is also called "prediction". And depending on whether it's happening between frames or within a single frame, people talk of "inter" resp. "intra" frame prediction.
One key observation worth taking note of right here is that both techniques work on pixel blocks, so called macro blocks. More precisely, when going to work, the encoder is dividing frames into square blocks of usually 16x16 pixels and employing its compression algorithms - lossiness and prediction - on those individually. This makes a lot of sense, e.g. when trying to keep track of parts of the image that don't change between frames, but is also the reason why one commonly seen compression artifact is "blockiness".
So let's look at this in a little more detail, specifically to understand why low picmip streams need substantially more bandwidth than higher picmip streams.
(2) How video compression works, roughly
(2.1) Lossiness and DCT
So how does the "lossiness" part work, in essence? One can't just throw away pixels, can one.
The trick is to find a representation of the image data that separates more noticeable from less noticeable parts. The keyword here is "discrete cosine transform" (DCT), which is kind of a Fourier Transform. And which represents the image data as a set of numbers. A matrix of numbers actually, called the "coefficient matrix" of the corresponding macro (pixel) block.
This matrix is then subjected to "quantization", which effectively amounts to throwing away a good deal of those numbers. And that's already the "lossy compression" part. Just throw away numbers, so that there's less data to transmit over the network or to store on disk. And on playback, reverse the cosine transform on that reduced data and (hopefully) arrive at a result that still looks reasonably good to the viewer.
Here's a nice link that gives a visual idea of how this works and what amount of compression can be achieved by quantization:
http://www.csc.villanova.edu/~rschumey/csc4800/dct.html
Look at the original picture of the lady at the top and then the three pictures of her at the bottom. In this example, the compressor works on blocks of 8x8 pixels and corresponding 8x8 DCT matrices, each making for 64 coefficients per macro block.
Now, the third image from the bottom is the result of throwing away 63 out of 64 coefficients. That is, the "bandwidth" is reduced to 1/64th of it's original size, which of course is a hefty compression rate. Accordingly, the image exhibits artifacts. Yet it's highly astounding that the image is still recognizable, even after discarding more than 98% of the original data. That's how nifty these compression techniques are.
Considering the artifacts, what you're seeing there is how colors are blurred into each other within each block. Which makes for a noticeable loss of visual detail. And how the edges of the blocks become visible. This is typical for situations when the compressor is throwing away "too much" data. Specifically situations when bandwidth is too limited and the compressor forced to discard more coefficients than it would normally do.
Then look at the following images. The second one from the bottom is compressed to 3% of it's original "bandwidth". Saying that 97% of the original image data was discarded. This image looks noticeably better than the other one while still exhibiting some visible artifacts. Whereas the last picture, compressed to 34% of the original "bandwidth", can already be hardly distinguished from the original.
So that's how the "lossy" part works. Yet, before moving on to "prediction", let's reverse the above observations. If stark compression introduces blur and blockiness, then how would the "ideal" image input look like for the compressor? Or put differently, what kind of original image would the compressor understand as "well compressed" already, in its original form? The answer is pretty much obvious I guess: the less detail the better. A macro block consisting of pixels of all the same color for example is already well compressed in its original form. It hence needs little intervention from the compressor. And can later be decoded by the client pretty much without loss.
Especially, we're seeing a first hint here why high picmip quake video is comparatively easy on bandwidth requirements. Because it's "well compressed" in its original form already, thanks to uniform looking surfaces. So not so much detail needs to be thrown away.
Now, before some of you go wisecracking on me along the lines: ok, the compressor introduces blur but high picmip does the same, so what's the difference? The difference is of course that the compressor is doing it uniformly. Contours, model detail, visual detail of everything is uniformly lost. As opposed to high picmip, where we're tweaking the video in a very controlled manner, only blurring out the very specific parts of the image that we consider redundant. Huge difference.
And then, for demonstration purposes, here an ingame pic directly taken from the 360p FaceIt stream
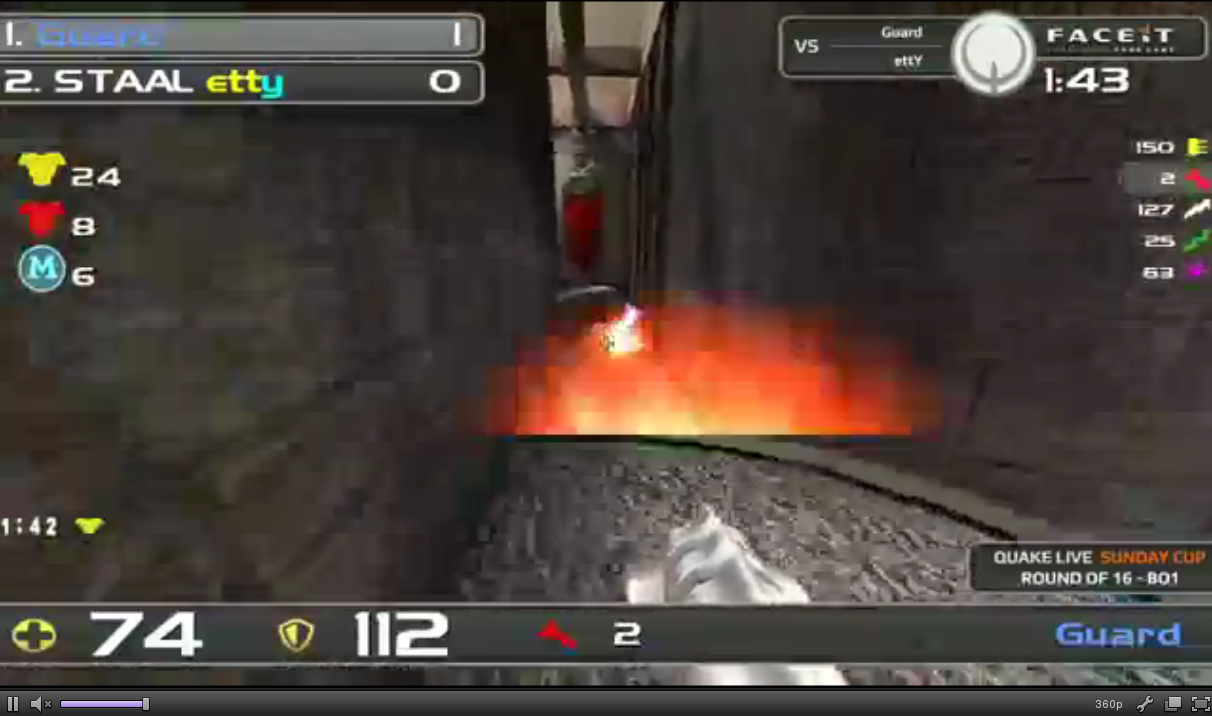
Are you able to recognize the artifacts? You should be, because they're all over the image, specifically the walls and floor. The macro block edges are clearly visible. The smear and blur inside each block is immense, there's hardly any detail left to discern. Except a couple of floor blocks maybe, during the encoding of which the compressor apparently thought it had a little more bandwidth to spend on those particular blocks. So altogether, a typical example for the compressor applying lossy compression way too much, resulting in disastrous image quality. Kind of a sad irony, isn't it? That the addition of more texture detail particularly on walls and floors, meant to enhance the visual experience, is actually ruining the video in its totality.
But wait ... how come the HUD still looks comparatively nice and sharp? Well, that's due to inter frame "prediction".
(2.2) Prediction
As seen above, if lossiness was all we had to rely on for compression the bandwidth reduction rates weren't quite so convincing yet if we were aiming for good results. That's why another key technique is employed: detecting equality or similarity of macro blocks and then just record the difference. The "delta".
Consider for example an image showing a person standing in front of a green wall. For a considerable part of the picture, the macro (pixel) blocks are literally all the same, just showing green wall. So the compressor fully encodes only one of those blocks by lossy DCT (see above) and then, for all those other wall blocks, just records "same same same ...". Which reduces bandwidth enormously. This technique, working on a single video frame or image, is called "intra frame prediction".
Now imagine the guy standing in front of the green wall again, but this time not only as a single image but as video. Let's assume for example that he's talking to us. Again, the wall for example doesn't change. But this time not only within one frame but also not from one frame to the next. So where the compressor could already reduce all those same blocks to basically one within a single frame, it can do the same thing also from one frame to the next. Again just recording "same same same ...". Which again reduces bandwidth enormously. Accordingly, this technique is called "inter frame prediction".
This kind of inter frame prediction is not all though. Because it's combined with "motion detection".
Motion detection is about how, in typical video, the camera is just panning and tilting around between scene cuts. So if for example the camera pans right, parts of the image are dropping out of the frame on the left when going from one frame to the next. While some new image portion is entering from the right. But most blocks stay the same from one frame to the next, given the panning isn't too fast. They have just moved. So if the compressor detects that, and he can in many situations, he just has to record one and the same displacement vector for all blocks that stay inside the frame. Again, a huge reduction in bandwidth.
All this prediction and detection is heavy on the CPU though. And for streamers, CPU time is limited because they need to push out their video in real time. As opposed to movie rippers for example, who can compress films in encoding runs spanning durations way longer than the actual running time of the movie. That's why they can benefit from better compression than streamers, because they can give the compressor all the computing time it needs to tweak the last bit out of it.
Especially, we're seeing one more reason now why quake video is heavy on bandwidth. Because when specing somebody, what we're doing in visual terms is following somebody who's constantly moving and flinging around a pov camera like crazy. This is pushing the compressor to its limits. And since it has to produce output in real time it can't really do that much motion detection. Resulting in more macro blocks needing to be fully DCT encoded and quantized and, to save bandwidth, accordingly more lossiness.
At the same time, while the above in-game image looked very bad, we now also know why this one, also taken from the FaceIt 360p stream, looks comparatively nice:
The reason obviously being that the compressor can perform huge amounts of inter frame prediction there. Most parts of that picture - i.e. most macro blocks - don't change between frames. They're static. Meaning that there's comparatively little computing to do and bandwidth needed for this kind of studio video.
Yet, similar reasoning also applies to the above ingame image. More precisely, to parts of that image like the HUD, which is comparatively sharp and good looking. That's because the macro blocks it is made of hardly change between frames. So the compressor can save bandwidth there by means of inter frame prediction and is accordingly easy on the lossiness, for those particular blocks. It's just not throwing that much data away, for those parts of the image.
(3) Quake streaming
Now, what does all this mean for the streamer?
The streamer usually tries to optimize video quality given the constraints he's operating under. One key constraint being bandwidth, be it his upstream bandwidth or the downstream bandwidth of his typical clients. And the other key constraint being computing power. Specifically so when not using an acceleration (MPEG encoder) card.
So let's assume the streamer is encoding for 720p. He's telling the compressor that he can use 2MBit bandwidth maximum, for example. And the CPU usage is controlled by one of the "presets" he's using. Typically somewhere in between "very fast" (little CPU usage but also little compression) and "very slow" (high CPU usage but also higher compression).
Now, assumed that the CPU is running pretty much at full throttle already (well, not really full, because that would introduce a high risk of lags), if the streamer's seeing artifacts in his video output, what can he do to improve video quality? There's only one option: increasing the bandwidth he's giving to the compressor, so it doesn't need to introduce so much loss.
And that's precisely what FaceIt and Zoot have done with their 720p streams. They've given them enough bandwidth to look good. As to some numbers, while I can't directly measure their bandwidth usage because it's maxing out my downstream, Zoot's resp. FaceIt's average usage should be somewhere between 2.6 to 3 MBit. Now compare that for example to Lanf3ust's high picmip 720p stream, which I actually did measure. It's running at an average 1.6MBit.
Brief digression here: personally, I'm highly recommending that Lanf3ust stream. It's beautiful to look at and appears to be running very smoothly.
So then, there you're having the cost of low picmip with a 720p stream: more than 1MBit difference in bandwidth usage between high and low picmip streams of the same resolution. Still, when giving their 720p streams all the bandwidth they need, why aren't streamers optimizing the lower resolution streams, too? Simple answer: because they can't.
(4) Twitch.tv
The thing is this: twitch allows streamers to send only one stream to their servers. In one resolution and quality. For this stream, twitch's servers merely function as "hub" that's just redistributing the stream to clients. Especially is this the one and only stream the broadcaster has direct control over and which he can optimize. In the flash player, you can recognize that stream by the "+" behind its resolution, like in "720p+". That's the stream which is coming directly from the streamer, passed through unaltered by twitch's servers.
For lower resolutions though the stream needs to be "transcoded". More precisely, one can't just scale the video down to other resolutions. Rather, the stream, as it's arriving at twitch, needs to be sent through the whole compression procedure again, just this time for a lower resolution. Another compression run now to be done on twitch's servers.
This is costly of course, in terms of computing resources. Which is the reason why twitch is offering this feature only to partners. Unfortunately, they're giving even partners no control over the quality of those lower resolution transcodes. Meaning that in terms of bandwidth and computing power, all streams are given a one-size-fits-all limit.
Again a brief measurement here: zoot's 360p stream, as encoded and transmitted by twitch, is running at an average of 640 KBit. Which is, very visibly, way too low given the complexity introduced by low picmip. But zoot has no way to increase that bandwidth or otherwise improve things. Simply because twitch is giving him no means of tweaking those transcodes in any way.
While at it, here's another peculiarity of twitch: it's sending out the streams in bursts. Those bandwidth measurements I mentioned above for example were averages measured over intervals of 40 seconds. But I also took 2 second measurements, which resulted in
~2 MBit bursts for Lanf3ust (average 1.6 MBit)
~1 MBit bursts for zoot's 360p stream (average 640 KBit)
So while these bursts apparently don't increase linearly, regular bursts of 400 Kbit above average happening every couple of seconds can be assumed in any case. And that's already the reason why I - with a 3 MBit downstream pipe - can't watch FaceIt's or Zoot's 720p streams without lags. Because even when running at an average of say 2.8 MBit those bursts go well beyond 3 MBit and are thus buffered by my ISP, due to throttling.
(5) Bottom line
So that's why things stand where they do. Quake video is complex and hard to compress even with high picmip, primarily due to all the fast "camera" movement. With low picmip, it's even harder to compress, that's why substantially more bandwidth is needed. But while streamers can optimize their main stream to look good, there's no way they can improve the lower resolution streams because those are resource-capped by twitch.
Bottom line being: when working with twitch, as a partner, and intending to stream at multiple resolutions be sure to optimize your video for twitch, and make it easily compressible. Because you can't optimize twitch for the demands of your video. Amen.
Edited by twister_ at 11:07 CDT, 1 May 2013 - 62529 Hits
{kind=link}
srsly though, very interesting read.
I hope it will help people stop whining about lag and quality without knowing shit.
Also, twitch only allows one stream per channel yes, but you can stream several channels at the same time :p
Here's a 3mins test of dual streaming, you can see the difference by yourself:
http://www.twitch.tv/nsx0r/b/396951531 ~3.5Mbps video + ~128kbps audio @ 720p
http://www.twitch.tv/nsx0r_lq/b/396951508 ~1.5Mbps video + ~96kbps audio @ 360p
btw, if anyone knows a speedtest URL hosted by twitch (for the viewer, not the streamer) it would be very useful.
The important thing is, people should stop thinking it's lagging on the streamer side, because it never is. Streamers can easily test their bandwitdh from their comp to the streming server and check if they have dropped frames.
At least I don't.
Even with retarded bandwidth.
Last words : if a stream is lagging for you, whining on the chat is useless. Just click on the reporting icon (the wrench icon on twitch's player) and report the problem.